Projet Loracrafft

image (c) Antoine Morandi
Le projet Loracrafft, lancé en 2022, a pour objectif de permettre la traduction, au moyen d'un smartphone ou d'une tablette, de textes écrits en hiéroglyphes égyptiens du Moyen Empire mot à mot et non pas signe après signe, comme quelques outils le font déjà aujourd'hui (lire notre article du 21 janvier 2025). Mais la nécessité de rendre disponible au logiciel embarqué un corpus qui sera essentiellement composé de dictionnaires, plus un grand nombre de textes de référence contenant translittérations et traductions, impose le choix de conserver toutes ces données sur un serveur distant doté de grandes capacités de stockage, d’où le choix que nous avons fait de mettre en place notamment une architecture client-serveur, architecture que nous présentons ici :
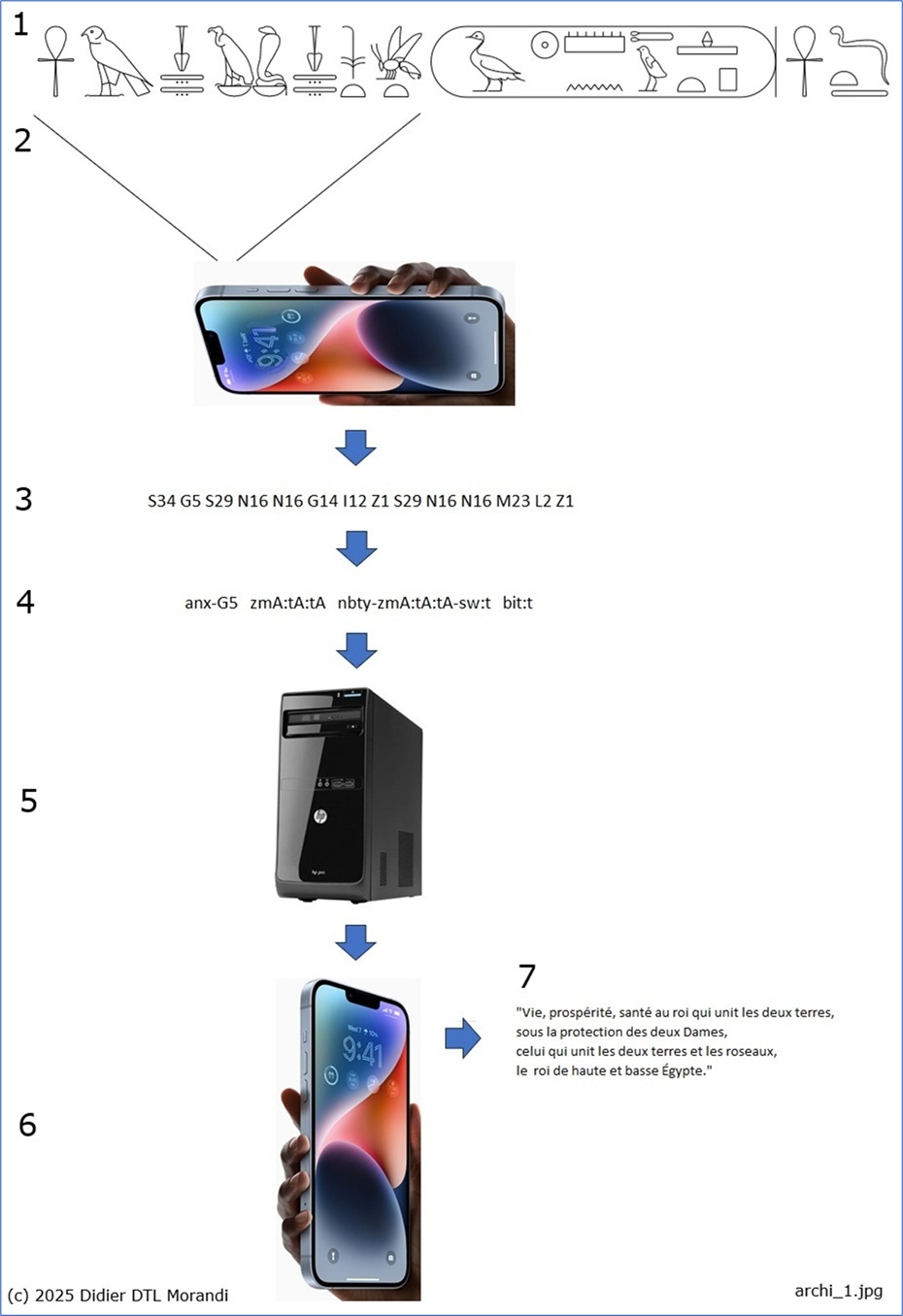
Le projet est découpé en lots, guidé par les études nombreuses déjà réalisées sur le sujet :
Lot 1 : lecture, reconnaissance, identification, classification Gardiner et translittération des signes
Lot 2 : traduction
Lot 3 : recherche documentaire dans le corpus pour proposer des extraits de textes contenant les mots traduits
Le lot 1 contiendrait 8 phases :
phase 1 : disponibilité des textes source
-
peinture murale
-
gravure murale
-
gravure sur pierre
-
peinture sur papyrus
-
peinture sur ostraca
-
peinture sur bois
-
photos
phase 2 : lecture du texte source par le smartphone ou la tablette
phase 3 : reconnaissance du ou des signes indicateurs du sens de lecture
phase 4 : reconnaissance des signes de façon groupée (cadrats...)
phase 5 : classification grammaticale
phase 6 : découpage en mots
phase 7 : conversion des mots en codes Gardiner
phase 8 : translittération
Le lot 2 consiste en :
phase 9 : traduction en français/anglais/allemand
phase 10 : affichage et lecture audio (en option) du texte résultant
Le lot 3 consiste en :
phase 11 : détection de textes du corpus contenant les mots reconnus
phase 12 : affichage/lecture du ou des textes en référence à la demande
L'idée, derrière la conception de cette application, est de fédérer des "buildings blocks" déjà existants pour réaliser certaines des phases ci-dessus :
Pour la phase 4, nous pensons à l'outil Tomb Reader de Morris Franken et Jan van Gemert
Pour les phases 5 et 6, nous pensons suivre les travaux de Serge Rosmorduc
Pour les phases 3 et 7, nous pensons à l'outil Hieroglyphs AI de Evgeniy & Alexander Sulimov
Pour la phase 8, plusieurs fichiers de données existent, notamment celui fourni par Raymond Monfort
Pour la phase 9, nous pensons utiliser pour la version française le Dictionnaire des hiéroglyphes de Yvonne Bonnamy, (c) 2013 Actes Sud, et l'annexe "Lexique égyptien-français" de l'ouvrage de Jean-Pierre Guglielmi, L'égyptien hiéroglyphique, (c) 2021 Méthode Assimil.
La phase 10 sera réalisée par l'équipement de lecture.
Pour les phases 11 et 12, une réflexion, complexe, est en cours car le projet entend permettre au logiciel du serveur de consulter de nombreuses bases de données lexicales réparties géographiquement un peu partout (TLA, VégA, Ramses, etc.) pour entraîner son réseau de neurones, et une fusion de tous ces corpus semble irréaliste. Leur interrogation à distance serait-elle envisageable, voire bénéfique ? Nous avons lancé des consultations. L'avenir le dira.
Rappel de la problématique d'identification[1]
A - un signe peut être :
-
un pictogramme, il exprime l'objet ou l'action dont il représente l'image
-
un idéogramme, il exprime une idée visible ou invisible
-
un phonogramme, il représente un ou plusieurs sons
-
un complément phonétique, il sert à différencier deux termes de prononciation différente mais représentés de façon identique
-
un déterminatif, il sert notamment à différencier deux termes de sens différent mais représentés de façon identique, ou indiquer un sexe
B - l'écriture hiéroglyphique se caractérise par l'absence
-
de séparation, d'espace entre les mots
-
de ponctuation, de marques de séparation entre les phrases
-
de caractères "majuscules"
-
de voyelles
-
d' "orthographe" (graphie) fixe
C - l'image d'un signe peut être altérée
D - un cadrat peut contenir plusieurs signes
E - distinguer cartouches, sérekh et hout
F - nécessité d'un corpus
G - nécessité de déterminer l'époque du texte pour en connaître les spécificités linguistigues
H - détermination des contextes temporels (perfectif, imperfectif)
I - propositions à prédicat adverbial vs nominal, avec ou sans lexèmes.
J - certains signes peuvent être abrégés, tel N25 :
![]() en
en
![]()
-
Lire notre article général du 12 janvier 2025 et celui (détaillé) du 21 janvier 2025.
-
Une revue des publications sur le sujet est maintenant disponible dans le forum.
Nous sommes à la recherche d'universitaires maîtrisant totalement le Deep Learning, et notamment la programmation des réseaux de neurones convolutifs avec mécanismes d'attention pour les lots 1 et 3, et la traduction assistée par ordinateur pour le lot 2. Nous contacter.

[1] Sources : Cours d'égyptien hiéroglyphique, Grandet-Mathieu (Khéops) / L'égyptien hiéroglyphique, JP Guglielmi (Assimil) / Cours d'épigraphie égyptienne, P. Le Guillou (association Imhotep) / Grammaire raisonnée de l'égyptien classique, Malaise-Winand (université de Liège) / publications académiques diverses.
[accueil]
page mise à jour le 01/02/2025 07:55