The Loracrafft Project

image (c) Antoine Morandi
The Loracrafft Project, launched in 2022, aims to
enable the translation, using a smartphone or tablet, of texts written in
Egyptian hieroglyphs from the Middle Kingdom word by word and not sign by
sign, as some tools already do today (read our
article of January 21, 2025). But the need to make available to the
device software a corpus that will essentially be composed of
dictionaries, plus a large number of reference texts containing
transliterations and translations, requires the choice of storing all this
data on a remote server with large storage capacities, hence the choice we
made to set up a client-server architecture, an architecture that we present
below:
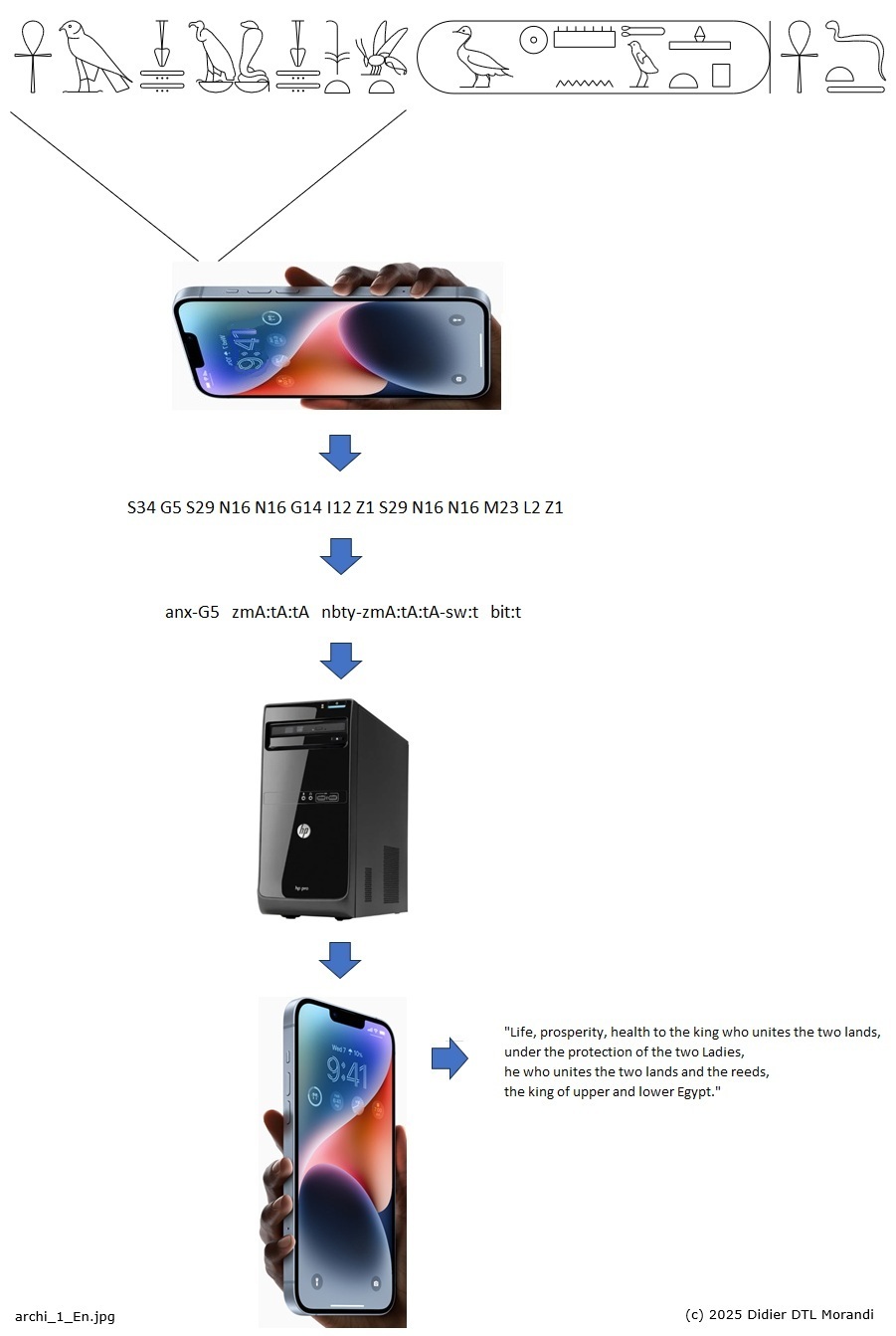
The project is divided into batch jobs, guided by the numerous studies already
carried out on the subject:
Batch 1: reading, recognition, identification,
Gardiner classification and transliteration of signs
Batch 2: translation
Batch 3: documentary research in the corpus to propose extracts of texts
containing the translated words
Batch 1 would contain 8 phases:
phase 1: availability of source texts
-
mural painting
-
mural engraving
-
stone engraving
-
papyrus painting
-
ostraca painting
-
wood painting
-
photos
phase 2: reading of the source text by the smartphone or tablet
phase 3: recognition of indicator signs for the reading direction
phase 4: recognition of signs in a grouped way (quadrats...)
phase 5: grammatical classification
phase 6: word division
phase 7: conversion of words into Gardiner codes
phase 8: transliteration
Batch 2 consists of:
phase 9: translation into French/English/German
phase 10: display and audio reading (optional) of the resulting text
Batch 3 consists of:
phase 11: detection of texts from the corpus containing the recognized words
phase 12: display/reading of the text(s) in reference to the request
The idea behind the design of this application is to federate already
existing "building blocks" to carry out some of the phases above:
For phase 4, we are thinking of the Tomb Reader tool by Morris Franken and
Jan van Gemert
For phases 5 and 6, we are thinking of following the work of Serge Rosmorduc
For phases 3 and 7, we are thinking of the Hieroglyphs AI tool by
Evgeniy &
Alexander Sulimov
For phase 8, several data files exist, including the one provided by Raymond
Monfort
For phase 9, we are thinking of using for the French version the
Dictionnaire des hiéroglyphes by Yvonne Bonnamy, (c) 2013 Actes Sud, and the
appendix "Lexique égyptien-français" of the work by Jean-Pierre Guglielmi,
L'égyptien hiéroglyphique, (c) 2021 Méthode Assimil.
Phase 10 will be carried out by the reading equipment.
For phases 11 and 12, a complex reflection is underway because the project
intends to allow the server software to consult numerous lexical databases
geographically distributed everywhere (TLA, VégA, Ramses, etc.) to train its
neural network, and a merger of all these corpora seems unrealistic. Would
remote questioning be possible, or even beneficial? We have launched
consultations. We'll see.
-
Read our general article of January 12, 2025 and the (detailed) one of January 21, 2025.
-
A review of publications on the subject is now available in the forum.
We are looking for academics who have a complete mastery of Deep Learning,
and in particular the programming of convolutional neural networks with
attention mechanisms for lots 1 and 3, and computer-assisted translation for
lot 2. Should you be interested, please
get in touch.
[home]
page updated on 2025-02-02 09:31